
Crawfish
App
- Category Development
- Client Not Disclosed
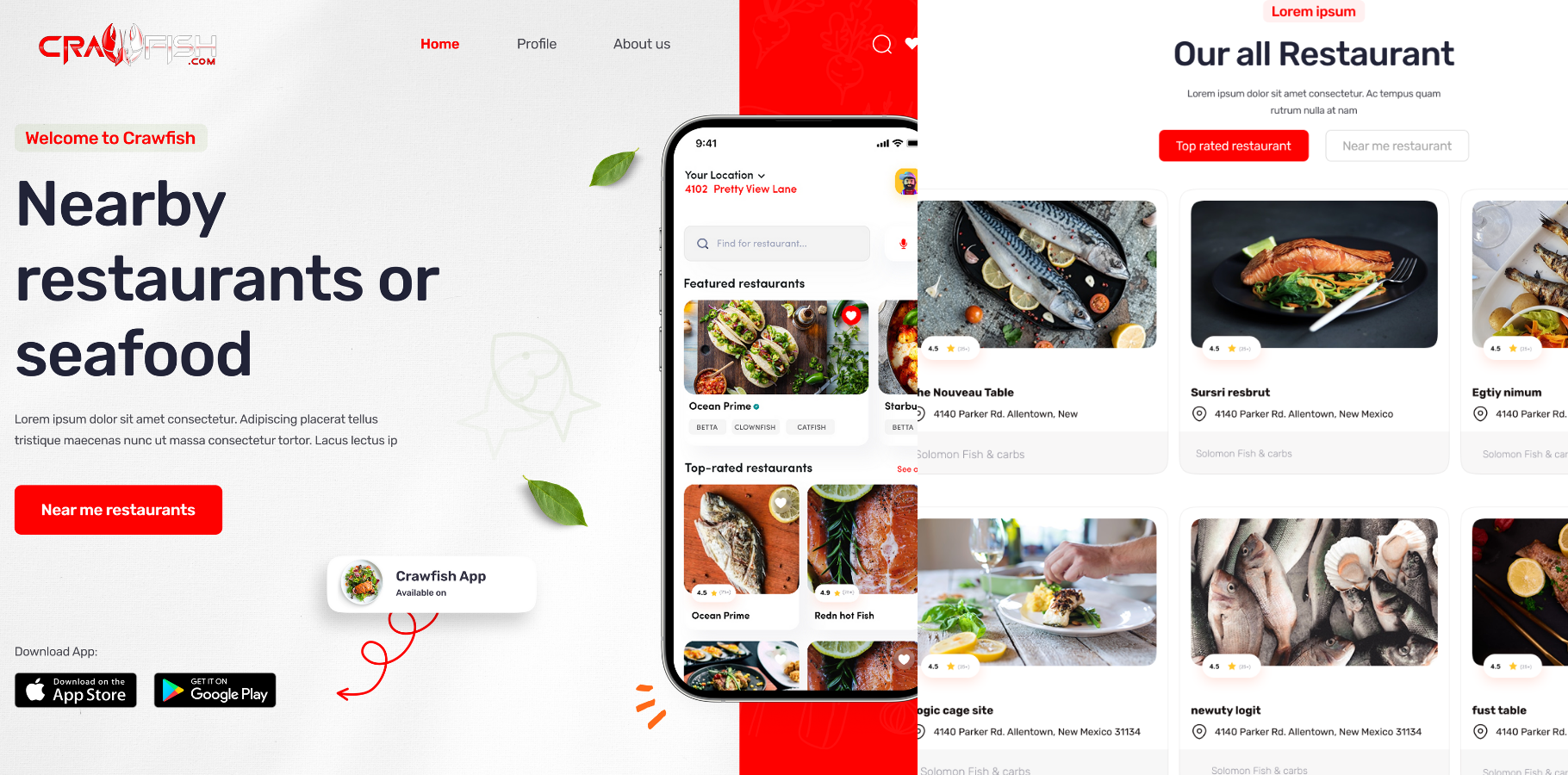
Introduction Of Crawfish
Crawfish is a web scraping and data aggregation tool designed to extract and organize restaurant information from various online platforms. It intelligently scrapes restaurant listings, menus, locations, and ratings, and compiles them into a structured format suitable for use in applications, dashboards, or business analytics. Crawfish helps centralize data from multiple sources, enabling users to discover restaurants efficiently.
Technologies Used in Crawfish App
- MongoDB
- React
- Node Js
-
 Flutter
Flutter
- HTML
- CSS
- JavaScript

Problem Solved by Crawfish
Crawfish solves the challenge of fragmented restaurant data across the internet. Restaurant information is often scattered across various websites (like Zomato, Yelp, Google Maps, etc.), making it difficult for businesses or developers to compile consistent data. Crawfish automates this process by scraping relevant details and presenting them in a usable format, reducing manual effort, saving time, and improving accuracy in restaurant discovery or data integration.





World Impact of Using Crawfish: By using Crawfish, businesses and developers can build smarter food apps, recommendation engines, or travel platforms that show comprehensive restaurant data in one place. This improves user experience, supports food delivery or tourism startups, and enables better data-driven decisions. On a larger scale, it helps bridge the gap between restaurants and digital platforms, giving even smaller establishments a fair chance to be discovered online.
Challenges Faced While Building Crawfish
Building Crawfish came with several significant challenges, especially during the data scraping process. Many websites implemented anti-bot protections such as CAPTCHAs, JavaScript rendering, and IP rate-limiting, making it difficult to access data reliably. Each platform also presented restaurant information in different formats, requiring custom scraping logic for each one. Additionally, the same restaurant often appeared on multiple sources, leading to duplication issues and the need for thorough data cleaning. Keeping restaurant details like menus, prices, and hours updated in real-time required regular crawling and scheduling. Legal and ethical considerations also played a role, as the scraping had to align with platform terms of service and data privacy rules. One of the biggest challenges was rendering the scraped restaurant data in a user-friendly UI—this involved mapping complex nested structures like categories, menus, and reviews, and in cases where scraping failed, integrating external APIs to ensure complete and accurate results.